Most Replit Agent users start with an idea. They describe the goal in natural language — without a repo, test suite, or chosen framework — and expect the agent to turn it into a functioning app. The result might be a website, slide deck, mobile app, several connected artifacts, or something else entirely.
Vibe coders are not usually checking diffs or test output. Success for Replit Agent is deceptively simple: the app should work when users click around.
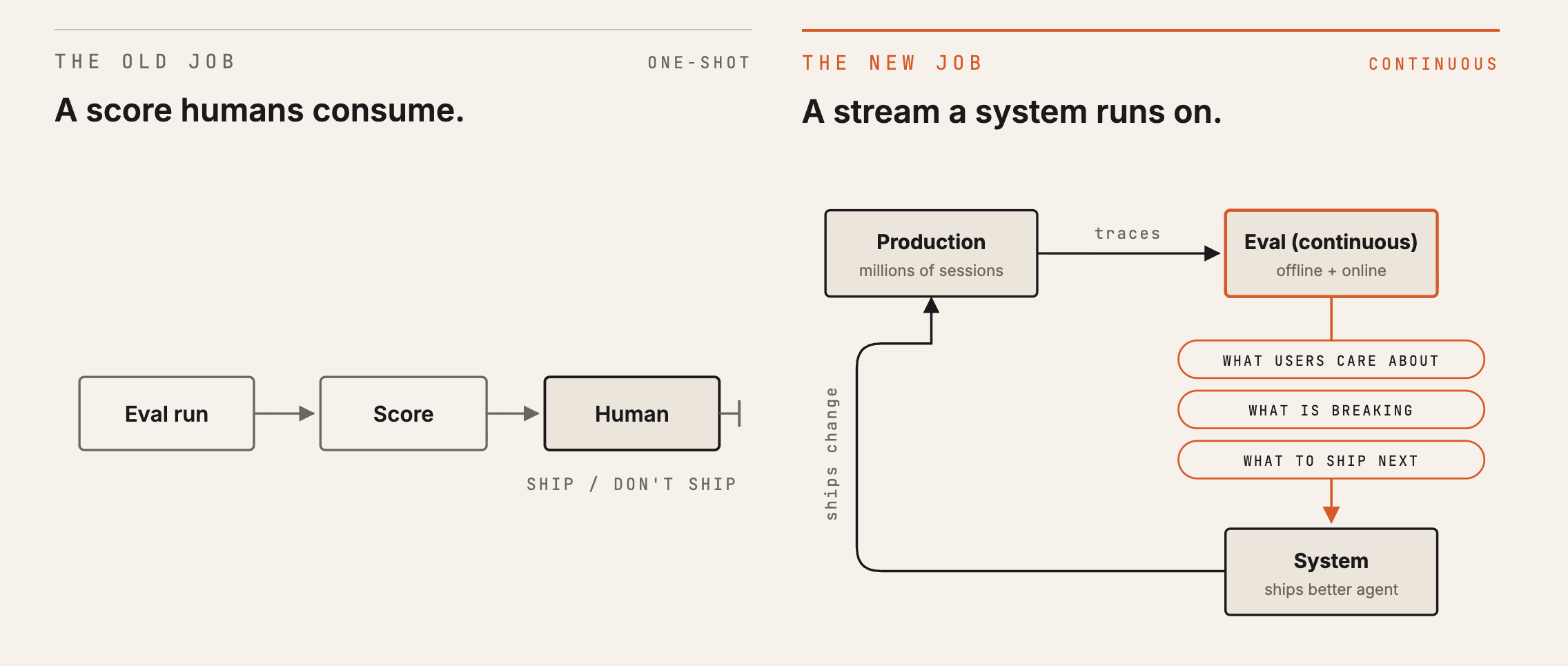
That changes the job of evaluation. A single score can help with a specific shipping decision, but it cannot tell us, week over week, whether Replit Agent is getting better for users. To answer that question, evaluation must become part of the improvement loop.

Evaluation has to do more now
Agent evaluation used to look like a one-way process: run the eval, produce a score, and make a shipping call. This works when releases are slow and the thing being measured rarely changes. It breaks down when models, prompts, tools, and product surfaces are all changing quickly.
The old loop made evaluation feel bounded. But Replit Agent changes too quickly for a single score to carry the whole decision. A score can compare two candidates on one slice of tasks. It cannot explain what users care about, where production is breaking, or what to improve next.
Evaluation had to move from launch check to improvement loop.
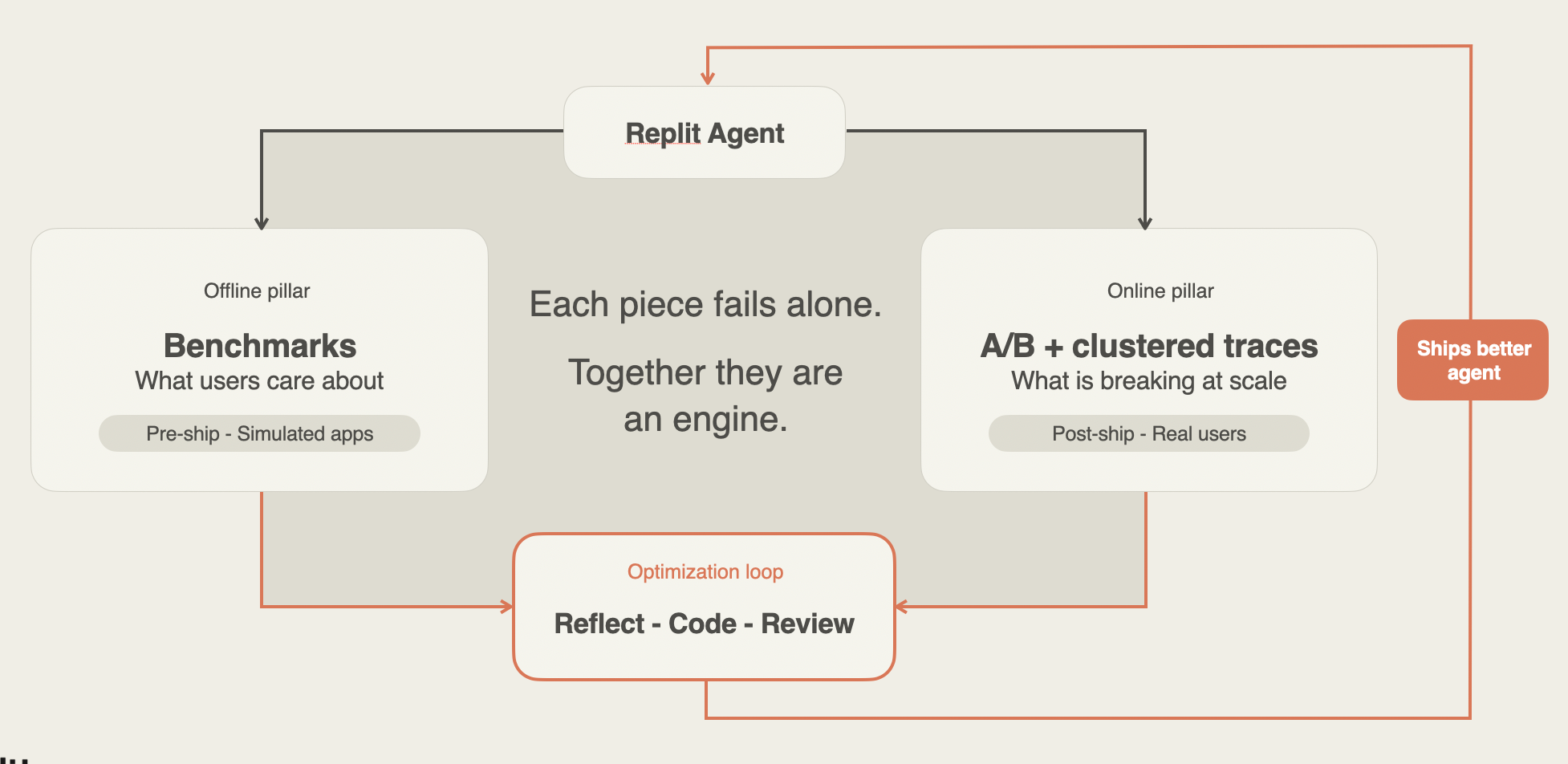
The system has two measurement pillars and one optimization loop. Offline benchmarks tell us whether candidate changes can complete simulated app-building tasks before we ship them. Online A/B tests and production traces show how real users are affected after the changes ship. Those signals then flow back into evals and shipping decisions.
No layer is enough on its own. Benchmarks catch regressions before release. A/B tests show whether production behavior moved. Trace clusters explain the failures under aggregate metrics. Human judgment keeps the improvement loop pointed at the right product and engineering outcomes. The shape is analogous to the Swiss cheese model in safety engineering: each layer has holes, but together they catch more than any one layer can.
Existing benchmarks stop short of the user
Agentic coding benchmarks such as SWE-bench [1] and Terminal-Bench [2] grade code in constrained, repeatable environments. These benchmarks are valuable and widely adopted, but they miss the signal a vibe coder cares about.
Replit Agent often creates the codebase from scratch. Users do not bring fixed routes, function signatures, selectors, or tests; they bring a product request. The agent chooses the stack, schema, routes, components, and interaction flows.
That creates a functional correctness gap. An agent can satisfy the local constraints of a coding benchmark and still fail at what the user sees: whether the finished app does what was asked. For vibe coding, the evaluation target is the artifact itself: does it load, does the core workflow work, and does the result match the request?
Introducing ViBench
The need for this style of end-to-end evaluation is precisely why we built ViBench [3], our public benchmark for vibe coding, measuring a simple but important signal: does the application built by the agent meet the spec?
ViBench starts with a plain-English product requirements document (PRD) drawn from anonymized Replit production traces. From there, the agent receives the PRD and builds a running app from scratch, without being constrained to the scaffolding, routes, or references that traditional coding benchmarks require.
However, the same flexibility that makes ViBench realistic demands an equally flexible eval agent, one that stays grounded in the PRD. In SWE-bench-style benchmarks, the project already exists, so the evaluation surface is fixed. In vibe coding, the agent picks the stack, routes, components, and flow. Evaluation has to explore whatever it invented.
To that end, each ViBench task pairs the PRD with a set of natural-language test plans that describe the feature-level interactions and assertions the finished app must satisfy. The eval agent uses Playwright as a flexible backbone, which lets it exercise complex features such as offline simulation, file manipulation, and multi-tenancy. Because it doesn't know the app's locators or structure a priori, it works in a notebook environment, progressively discovering how the app is built and interacting with it step by step, an approach drawn from Replit's earlier research on automated self-testing [4].
Running ViBench, and our evals in general, at Replit scale also demands strong infrastructure support [5]. Internally, we lean on the same production infrastructure that lets us spin up isolated, well-resourced sandboxes for building apps and running our agents. Because we can quickly fork those sandboxes [6], we run much of the evaluation in parallel, without risking cross-evaluation contamination.
Beyond building apps from scratch, the same ViBench foundation, a natural-language PRD graded by natural-language test plans, adapts to a range of vibe-coding scenarios. To evaluate how an agent works within an existing app, closer to Replit's mid-trajectory workloads, we start it on an existing codebase and measure how well it ships feature extensions from a feature PRD. That codebase can come from our own reference implementations or from apps the agent vibe-coded itself, which we call Vibe-to-ref and Vibe-on-Vibe in our publication. When we ship new product surfaces, the same backbone lets us quickly derive new problems to evaluate novel interaction patterns, as we did for Agent 4's parallel-and-merge and subagent decompositions.

Early ViBench results gave us two useful lessons. First, frontier coding-benchmark scores do not always transfer to full app building, especially for open-weight models. Second, most models get worse when extending their own code. Errors compound. Together, those lessons give us a better hill to climb: not just writing code that passes tests, but building apps that can survive the next user request.
A/B is how we keep ourselves honest
We trust offline evals deeply, but they are not the only judge. We have seen enough agent updates look good in controlled settings, only to regress real user behavior, to know that production needs its own measurement layer.
Users are unscripted, always on, and operating at a scale no offline benchmark can fully reproduce. They abandon projects, change their minds, combine features in surprising ways, and discover failure modes we did not know to test.
So we A/B most agent-affecting updates: prompts, tools, harness revisions, model swaps, and larger behavior changes. Multiple experiments often run concurrently — with attribution kept clear to avoid hiding interaction effects. A/B tests surface user behavior, sentiment, and success: did users keep going, did cost behave unexpectedly, did sentiment move, and did users ship something?

A challenge with A/B testing is that results are hard to interpret. If run duration goes up, did the agent do more useful work, or did it get stuck? If cost goes down, did we improve efficiency, or did the agent silently stop doing something valuable? If sentiment drops, which use cases regressed, which failure modes are new, and which users gave up?
Telescope: what is breaking
A/B testing tells us when production behavior moved. Telescope — our system for trace analysis and clustering — helps explain why.
At production scale, no engineer can read every trace. Telescope organizes repeated patterns into issue clusters that engineers and agents can act on. It summarizes failure trajectories, embeds them, clusters similar cases, and classifies new sessions as the distribution changes. The goal is not just to count failures, but to discover the ones hidden in plain sight.
Telescope uses short, evidence-grounded facets inspired by the same bottom-up approach as Clio [7]. For traces, it reconstructs the session from user messages, visible agent replies, tool calls, errors, metadata, and other context. From there, Telescope summarizes what went wrong, embeds those summaries, and uses density-based clustering [8] to form emergent issue groups.
Facets make investigation faster, especially when clustering alone is not enough. When support reports point to a broad issue, such as port failures, engineers and agents can search the compact layer first, explore the relevant facets, and then drill into representative sessions with the logs and observability context needed to explain it.
In aggregate, the same structure turns scattered failures into product questions: which workflows dominate, which get abandoned, what breaks repeatedly, and whether a mitigation is shrinking the intended cluster.
For more on this underlying architecture, see the in-depth post on Topics from our collaborators at Braintrust [9].
The loop: from evidence to agent improvements
Once measurement exists, the bottleneck moves. ViBench, A/B tests, and Telescope can tell us what failed, where it failed, and how often it is happening. We still have to turn that evidence into plausible fixes.
We turn to a self-improvement loop to address this. The operating principle is simple: if agents are useful for building software, they should also be useful for improving the agent. Each pass starts by reading production logs, trace clusters, and recent failures to find a hypothesis worth chasing. Then it builds a candidate, opens a draft PR with the reasoning attached, measures the result against ViBench, A/B results, trajectory data, and recent baselines, and recommends whether to ship, iterate, or drop it.
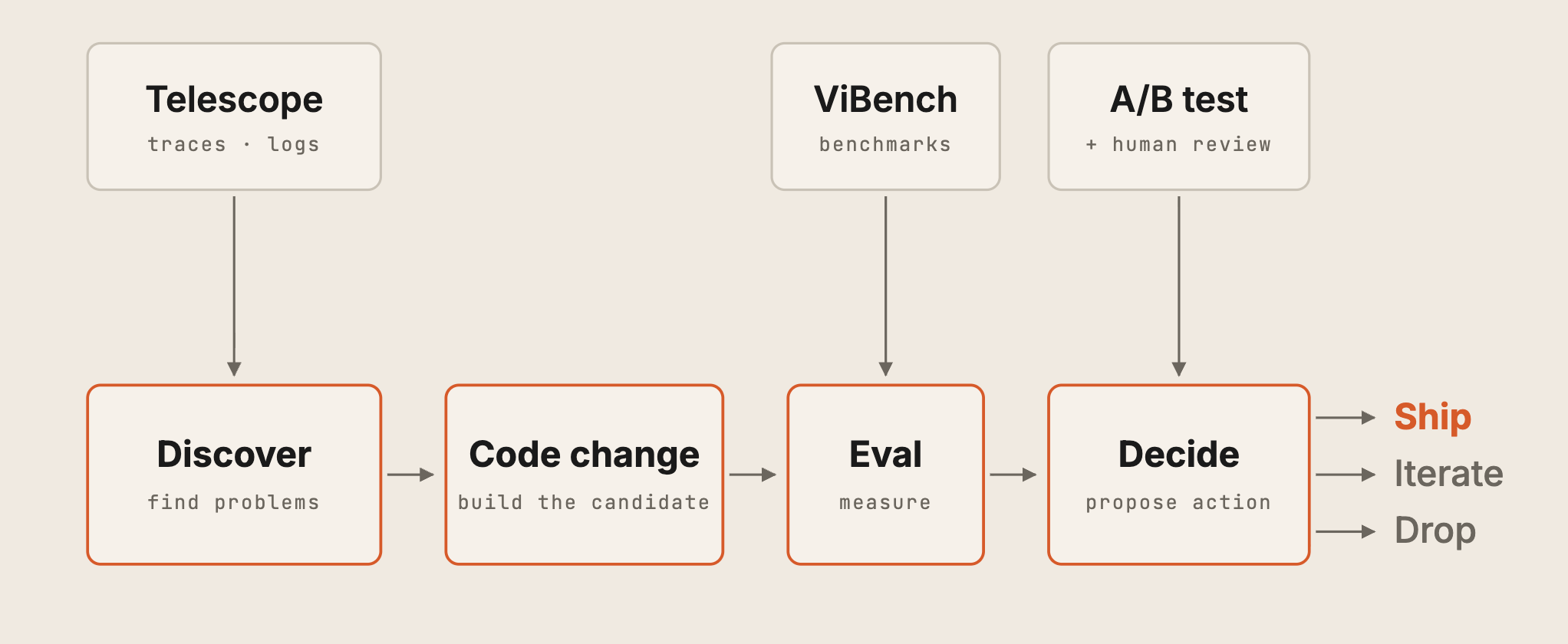
Shipping does not become automatic. The loop can prepare the evidence and first-pass implementation; engineers still review the result and own the launch decision.
Each run records what it tried and what happened, including failures. That record improves the loop over time: future runs can reuse what worked, avoid known dead ends, and propose changes that generalize.
Agent iteration gets faster without giving up engineering control. Given a new model, product surface, or reliability goal, the loop can proactively find prompt edits, skill proposals, tool fixes, and harness changes while engineers keep the system pointed toward the larger product optimum.
A concrete example
One recent run started with a small but growing Telescope cluster. Environment setup was silently degrading across a long tail of cold-start scenarios. These sessions were not obvious from aggregate metrics, but the cluster showed a pattern worth investigating.
After surfacing the pattern, the loop read the affected trajectories, proposed a patch, added a regression test, and ran the candidate against ViBench to confirm that the happy path did not regress. Engineers reviewed the evidence, approved the change, and pushed it to production the same day.
After the patch shipped, sentiment recovered and affected users were unblocked. This is the shape we want — a loop that finds a real failure pattern, connects it to affected users, proposes the right level of fix, and brings back enough evidence for a human to decide whether to ship.
Where human taste still matters most
Much of this can run autonomously: clustering failures, proposing hypotheses, building candidates, running evals, and assembling evidence. Humans still set the direction and gate most exits, including:
- Hypothesis selection. A system can surface a thousand failures, but humans decide which questions deserve the loop's overnight budget. Not every cluster is equally important, and not every regression points to the right product problem.
- Implementation architecture. Traces might show that users are abandoning a workflow, but deciding whether to smooth that path, change the agent's behavior, or redesign the surface is an engineering and product judgment.
- Eval curation. This is not administrative work; it shapes the hill the agent climbs. If the eval rewards the wrong behavior, the optimization loop will faithfully optimize toward the wrong thing.
- Launch approval. Shipping an agent change is not just reading a number. Launch approval means reading the evidence, understanding the blast radius, deciding whether the risk is acceptable, and owning the rollout.
That balance matters: the loop can do more of the search, measurement, and synthesis. Engineers still choose the direction, make the product calls, and decide what ships.
Closing the loop
Evaluation is no longer just a gate before launch. It helps decide what to fix, what to test, and what to release.
The work is not to produce a better number. It is to turn user failures into better releases, so more ideas become apps people are proud to publish.
We're excited to keep pushing the frontier of autonomous agents, with a focus on reliability for the most complex coding tasks. If you are interested in working on autonomous software engineering agents, our team is hiring; reach out to [email protected].
References
[1] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
[2] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
[3] ViBench: A Benchmark on Vibe Coding
[4] Enabling Agent 3 to Self-Test at Scale with REPL-Based Verification
[5] Quantifying infrastructure noise in agentic coding evals
[6] Inside Replit’s Snapshot Engine: The Tech Making AI Agents Safe
[7] Clio: Privacy-Preserving Insights into Real-World AI Use
[8] Hierarchical Density Estimates for Data Clustering, Visualization, and Outlier Detection
[9] How we made continuous trace intelligence possible at scale