Find Duplicate HubSpot Deals with AI


Introduction #
Identifying duplicate deals in your HubSpot CRM can be crucial for maintaining clean data and accurate reporting. This template uses the HubSpot API to fetch deals, analyzes them for potential duplicates using OpenAI, and exports the results to a CSV file.
Using our template, you can have a HubSpot Deal duplicate finder running and exporting data to a CSV file in less than 5 minutes.
Getting started #
To get started, head to the template below and click "Use template":
Create a Private app in HubSpot #
Log in to your HubSpot account and navigate to Settings > Integrations > Private Apps
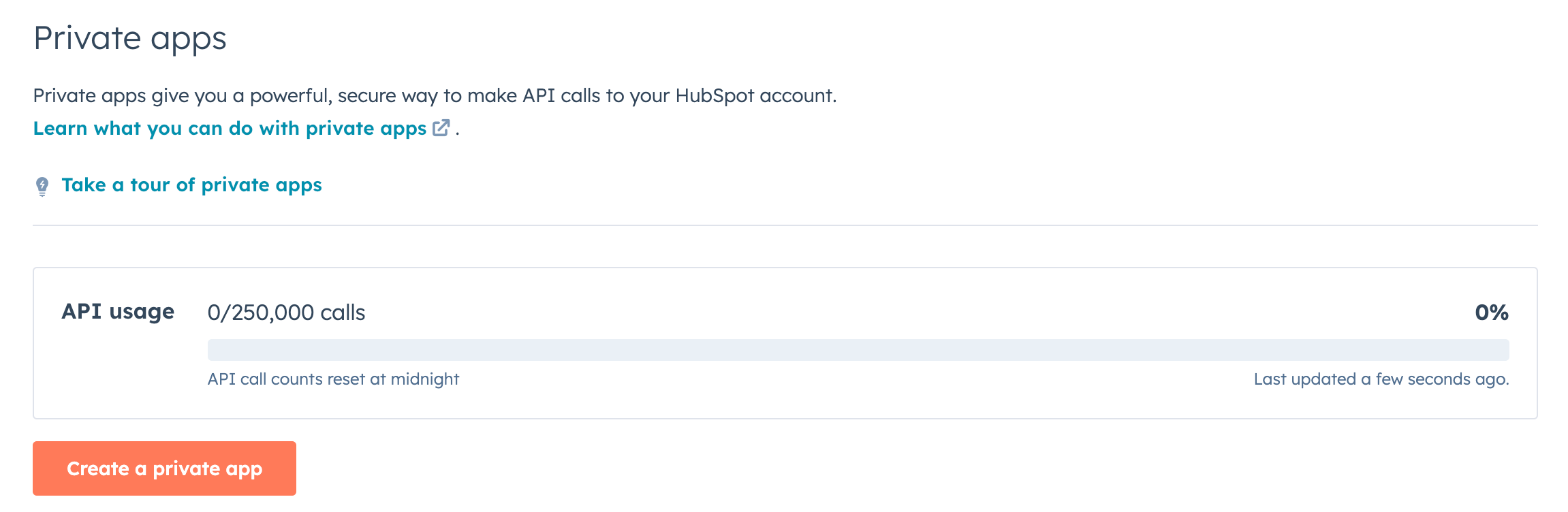
Click "Create a private app” and set a name for your app.
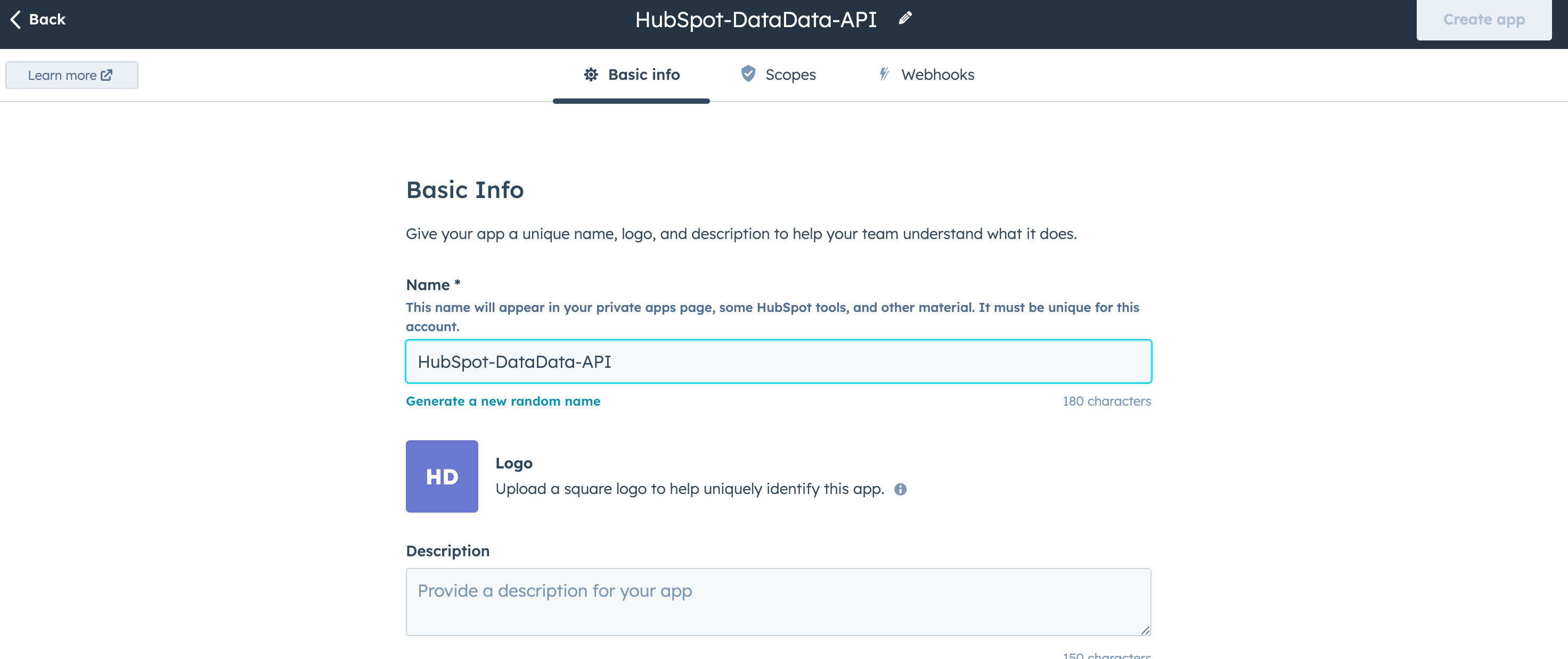
Set the necessary scopes (you'll need access to deals, contacts, companies, and owners).
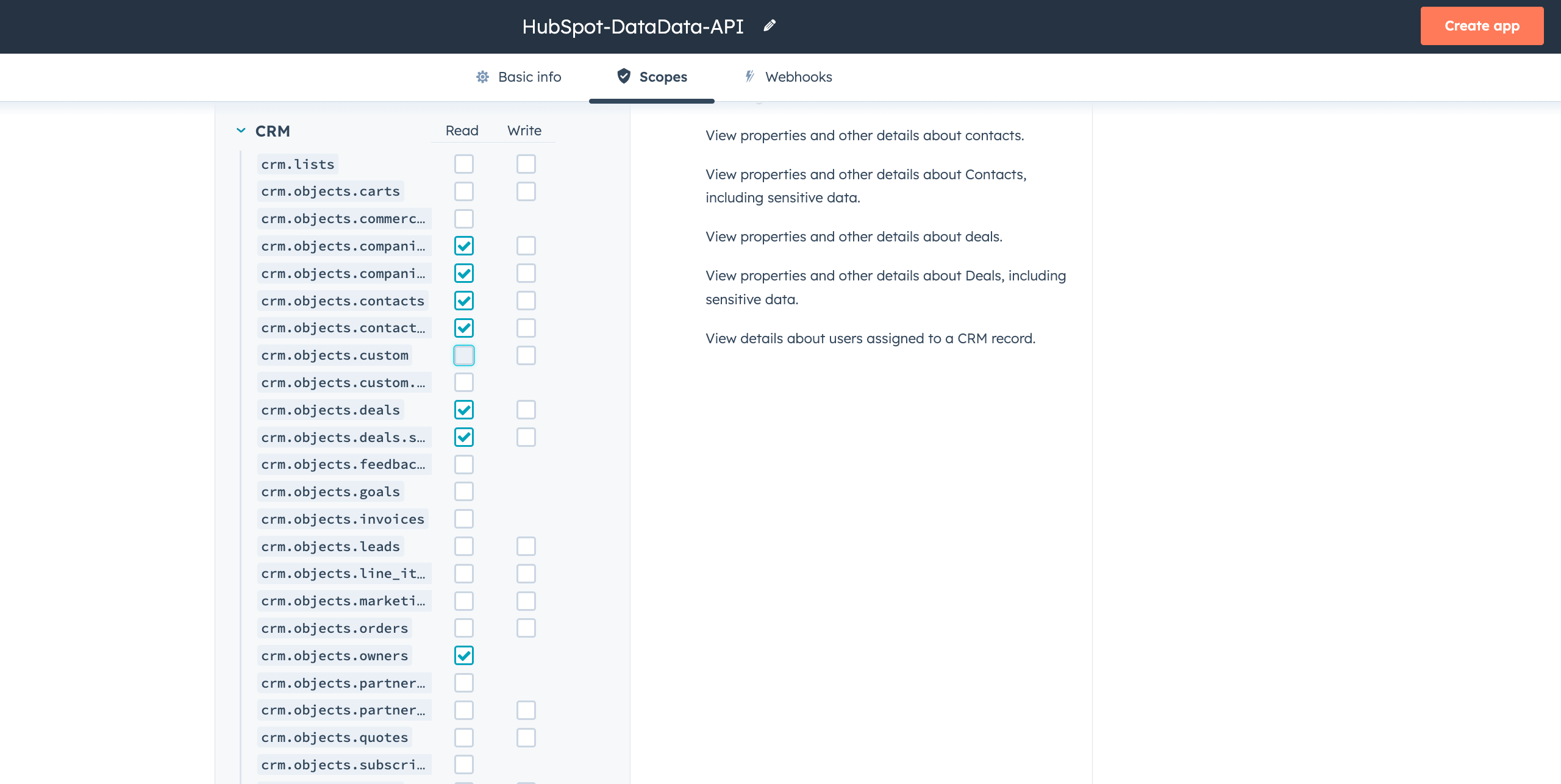
Once your scopes are set, click Create app. You'll receive a private app access token.
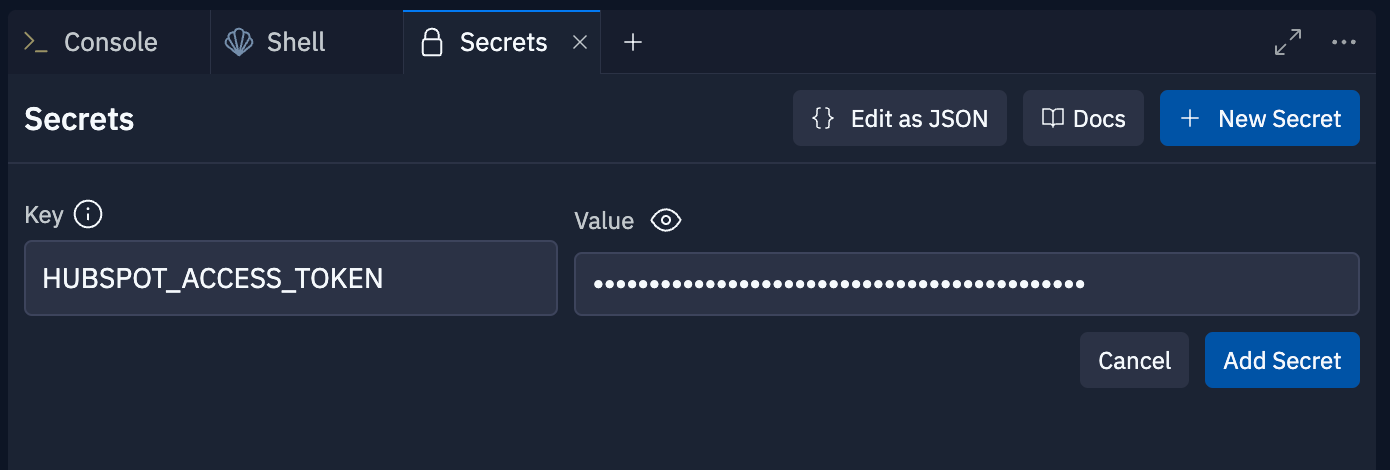
To keep this secret safe, add it to the Secrets tab in your Repl. In the bottom-left corner of the Replit workspace, there is a section called "Tools."
Select "Secrets" within the Tools pane, and add your Private App access token to the Secret labeled HUBSPOT_ACCESS_TOKEN.
Set up OpenAI API access #
Log in to your OpenAI developer portal and navigate to API keys. Click on the button Create new secret key in the top right corner and then again in the modal after you name your key.
Copy the secret key to your clipboard. Again, to keep this secret safe, let’s also add it to the Secrets tab in your Repl. Head back to the bottom-left corner of the Replit workspace, to "Tools."
Select "Secrets" within the Tools pane, and add your API key to the Secret labeled OPENAI_API_KEY.
Your secrets tab should look like this after adding both your HubSpot Private App key and your OpenAI API key.
Running your duplicate finder #
Once you have your application configured and tokens set, you can hit Run (⌘ + Enter) in Replit to execute main.py. The script will:
1. Prompt you to enter the number of deals to fetch from HubSpot
2. Fetch and process the deals
3. Identify potential duplicates using OpenAI's GPT model
4. Export the results to a CSV file
Here's a breakdown of the main components:
Fetching deals from HubSpot
The fetch_deals() function in hubspot_client.py uses the HubSpot API to retrieve deals:
Identifying potential duplicates
The compare_deals function in duplicate_finder.py uses OpenAI's GPT model to compare deals:
Note: This part of the script uses OpenAI which will incur a cost on your OpenAI account. If you would like to increase accuracy of the duplication detection, switch out this line for the most powerful OpenAI model:
model="gpt-3.5-turbo" or make edits to the prompt to be more specific to your goals.
Exporting results to CSV
The export_to_csv function in csv_exporter.py writes the results to a CSV file:
This script will generate a csv with the following columns:
- ID
- Name
- Company
- Close Date
- Amount
- Stage
- Owner
- Potential %
- Top Duplicate Deal
- Top Duplicate Deal - Company
- Potential Duplicates
Tip: If you want to edit your script or the final columns that will be written to your CSV file, ask Replit AI to make some edits or suggestions.
What's next #
Now that you have a working HubSpot Deal duplicate finder, you could consider the following enhancements:
- Add a web interface to trigger the duplicate finding process and display results.
- Implement more sophisticated duplicate detection algorithms.
- Add functionality to automatically merge or resolve duplicate deals in HubSpot.
- Set up scheduled runs to regularly check for duplicates.
- Integrate with other CRM systems or data sources for more comprehensive duplicate detection.
- Use the exported CSV data to create visualizations or reports on duplicate deals.
If you’d like to speak with the Replit team on how you can make the best use of Replit, feel free to schedule some time here. We can walk through your use case and point out the best ways to implement them.
Happy coding!