How to Enrich Target Accounts with AI



Introduction #
Revenue Operations and Marketing spend tens of thousands of dollars a year on data enrichment and the process is slow. This guide will show you how you can launch an app that can enrich data on any list of target accounts and companies, 100x faster and 1,000x cheaper.
Using Replit and OpenAI’s API, you’ll create a tool that allows users to upload a CSV file containing company website domains and enrich it with custom information extracted from those companies’ websites, using the power of large language models.
Example use cases:
- Check the company's website to see if they have a blog
- Infer what industry the company is in based on their website
- Understand what primary product or service is offered by the company
- Analyze language used by competitors
The web app can be invaluable for market research, lead generation, and competitive analysis tasks. The possibilities are endless!
By the end of this guide, you'll have a web application that can:
- Accept CSV file uploads containing company domains
- Scrape the websites of these companies
- Use OpenAI to generate enriched information based on the scraped content
- Add the enriched data back into your CSV!
Note: You will need a Replit Core or Teams account to deploy the web application.
Getting Started #
To access the code for this project, for the code for the template by heading to this link and clicking green Fork button to bring the starter code into your account.
Set Up Your OpenAI API Account
Before we begin with the Replit project, you'll need to set up your OpenAI API account. You can follow the steps here: OpenAI Developer Quickstart. To summarize:
Create an OpenAI Account:
- Visit the OpenAI website and sign up for an account if you don't already have one.
Sign In to Your Account:
- Once you have an account, log in using your credentials.
Navigate to API Keys:
- After logging in, go to the OpenAI Platform.
- Click on the dashboard button on the top bar.
- Then select “API keys” from the options on the left side of the screen.\
Create a New API Key:
- On the API Keys page, you'll see an option to create a new API key. Click on "Create new secret key."
- The system will generate a new API key for you. Be sure to copy and securely store this key, as it will only be shown to you once.
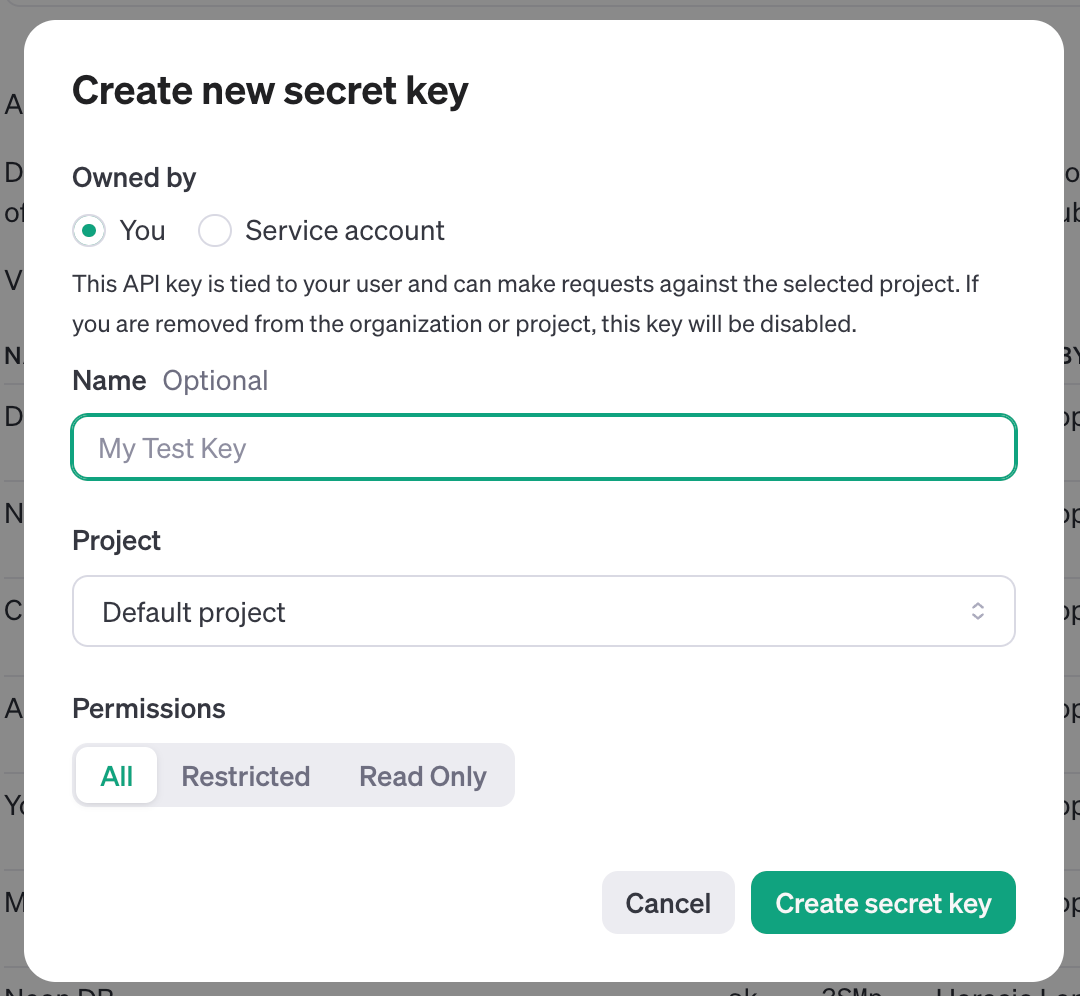
Secure Your API Key:
- Treat your API key like a password. Do not share it publicly or hard-code it into your applications. You’ll use Replit’s Secrets tool to securely manage it.
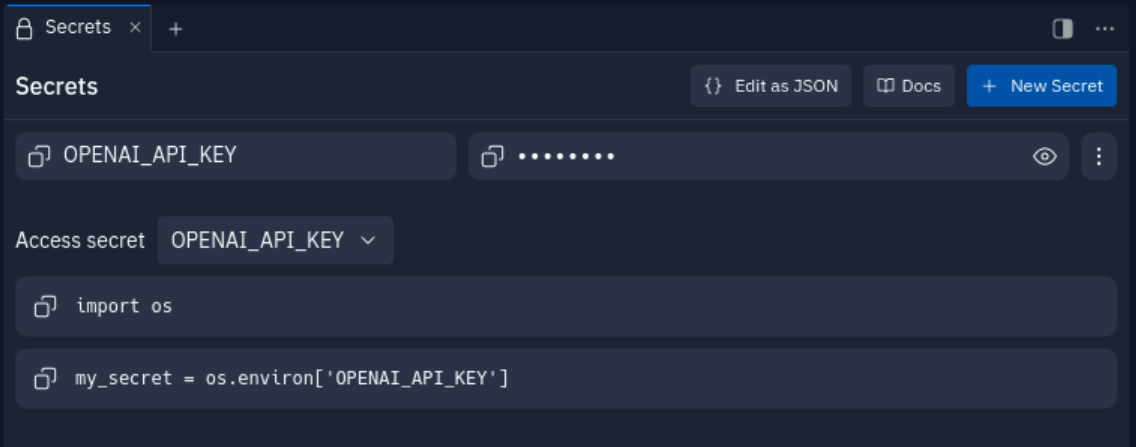
- Copy the secret key and add it to Replit's Secrets tab as OPENAI_API_KEY.
Set Up Your Replit Project
- Fork the template linked at the start of this Guide or by following this link
- In your forked Repl, to keep your OpenAI API key secret safe, add it to the Secrets tab in your Repl. In the bottom-left corner of the Replit workspace, there is a section called "Tools." Select "Secrets" within the Tools pane, and add your OpenAI API key to the Secret labeled OPENAI_API_KEY.
Running Your Application
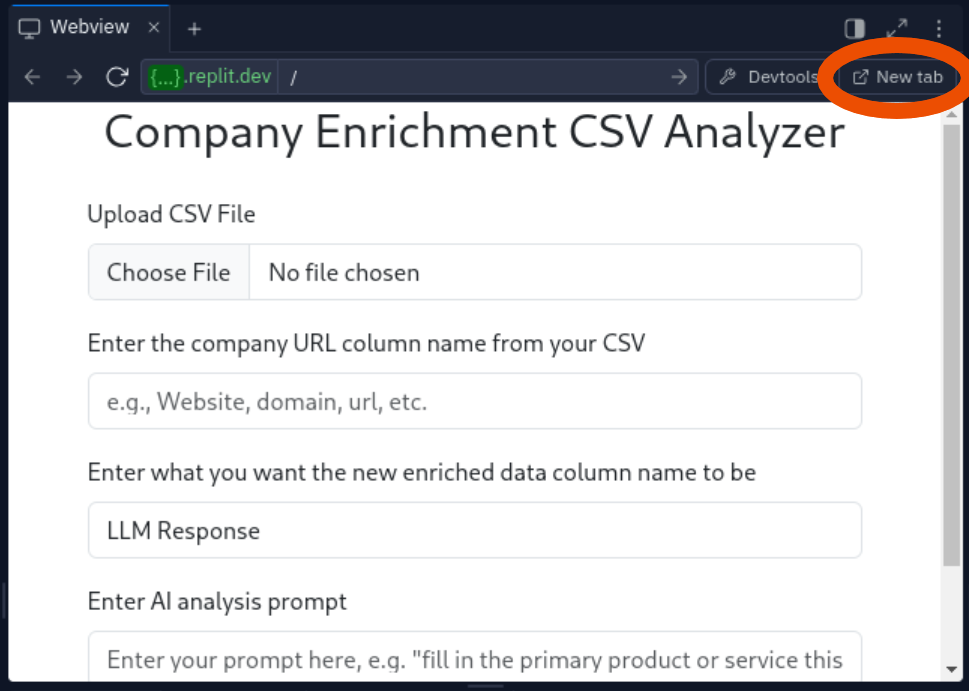
- Click the "Run" button in your Repl to start the Flask application.
- You should see a "Serving Flask app 'main'" message and other debugging logs in the Console.
- Click on “New tab” within the Webview tab to open the application in a new browser window.
Deploying to Production #
Setting Up Replit Deployment
In order to use your company enrichment tool going forward, you’ll want to deploy it on Replit (as a reminder, deploying an application requires a Replit Core or Replit Teams subscription).
Open a new tab in the Replit Workspace and search for “Deployments” (or find “Deployments in the Tools section near the bottom of the left-hand pane).
In your Repl, open the Deploy tab. Choose “Autoscale” as your deployment type.

Keep the default deployment settings. They should be more than enough resources for now and you can always come back and edit the settings later.
Click the blue Deploy button to start your Autoscale deployment.
Let it run until it is complete and you get a new, production URL.
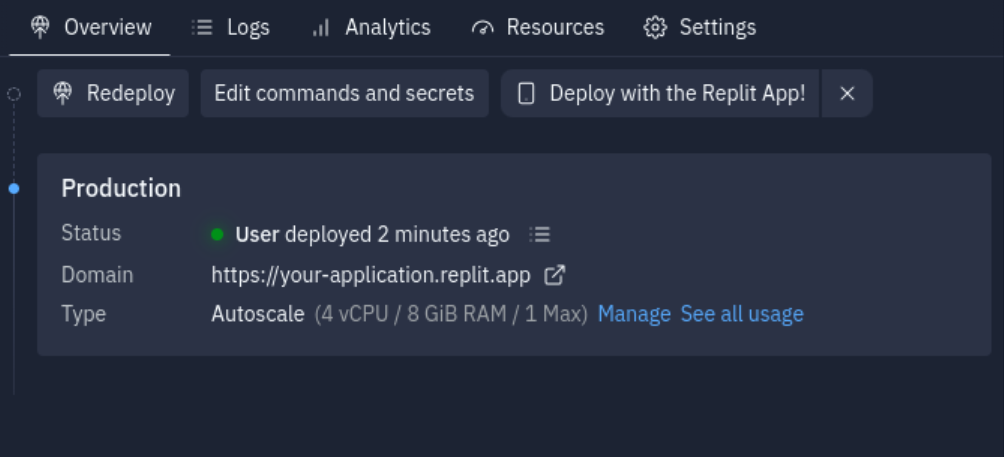
Your company enrichment web app is now deployed and ready to handle your prompts!
Using the Company Enrichment CSV Analyzer #
To use your deployed company enrichment CSV analyzer:
- Open the application URL in a web browser.

- Upload a CSV file containing a list of company domains
- Enter the name of the column header in your CSV that contains the company domains.
- Enter the name that you want the new column with enriched data to be called
- Enter a prompt for the information you want to extract about each company, i.e.:
- “Fill in the primary product or service this company provides”
- “Infer what industry this company is in”
- “If available, fill in the state the company is headquartered in. Format the state as its 2-letter code, for example use ‘OR’ for Oregon.”
- Click the "Analyze Company Data" button.
- Wait for the processing to complete. The enriched results will be displayed on the page.
- To download your CSV with the new enriched data column, click the green “Download results” button
Customizing the Application (Optional) #
By now you should have a working web application. If you’d like to understand what’s happening in the code and potential ways to extend or remix this template, the following sections cover that. Feel free to skip to the Conclusion if you are happy with the application as is.
Understanding The Code
The main components of the code are:
- main.py: The main Flask application file
- templates/index.html: The HTML template for the web interface
Let's break down the key parts of main.py.
Importing Dependencies
This section imports all necessary libraries, including Flask for the web application, BeautifulSoup for web scraping, and the aiohttp library for making HTTP requests, and the async OpenAI API.
Flask App Configuration
Here, we configure the Flask app, setting up the upload folder, secret key for session management, and maximum file size for uploads (16MB). We also initialize the OpenAI client.
Web Scraping Function
This function takes a url, scrapes the homepage and about page, and returns the text content included on those pages. We also use asyncio in order to speed up the time spent scraping by allowing for multiple sites to be scraped at once.
CSV Processing and OpenAI API Integration:
This function reads the CSV file, processes each domain, scrapes the website content, and sends it to the OpenAI API for enrichment. It returns the enriched results for each domain.
File Upload and Processing Route:
This route handles file uploads, validates the CSV file, processes it using the OpenAI API, and returns the enriched results.
File Download Route:
This route handles downloading the modified CSV file. It checks the session data for the new CSV content and downloads it to results.csv
Main Application Entry Point:
This section ensures the upload folder exists and starts the Flask development server on port 5000.
Understanding these components will help you navigate and customize the application to suit your specific needs. For example, you could modify the scrape_all_domains() function to target different pages or extract specific information from the websites. Similarly, you could adjust the OpenAI API prompt in process_csv_with_llm() to get different types of enriched information about the companies.
Remixing or Extending the Application
Using a different LLM
The web app could just as easily use a different LLM, such as Anthropic’s Claude Sonnet 3.5, or Google’s Gemini. While the instructions to convert the app to working with their APIs is beyond the scope of this guide, anyone should be able to figure out how to do it with relative ease.
HINT: use Replit’s built in AI Chat feature to ask the AI how to convert the app to working with your preferred LLM.
Adding additional functionality
The app could easily be extended to add additional functionality. Some ideas here might include:
- Adding a column to have the AI express its confidence in its results, i.e. if you prompted the AI to grab the state that the companies in your list are headquartered in, you could have it add a column next to the state column that shows, on a percentage basis, how confident it was that the state it input was accurate
- Convert the app to analyze people (leads or contacts) instead of companies
- A more advanced user could create an integration between this app and a CRM like Salesforce or HubSpot, and have the analysis trigger in near real-time upon company/account creation
We’re sure there’s 1000 more ideas you’ll have! Feel free to take our template and run with it!
Conclusion #
You now have a powerful target account enrichment tool that can automatically gather and analyze information about multiple companies using their website content. This tool can significantly speed up research and analysis tasks for various business applications.
Some potential use cases for this bot include:
- Generating company profiles for lead qualification
- Analyzing competitors' product offerings
- Identifying industry trends across multiple company websites
Feel free to further customize and expand the functionality of your app to suit your specific needs. Happy enriching!