Community





1

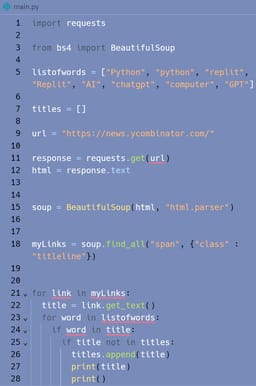
Scraping (Day 96_100Days)This Python code scrapes the website "https://news.ycombinator.com/" using the requests library and then parses the HTML content using BeautifulSoup. It then searches for specific words in the titles of the articles on the website. If a title contains any of the predefined words (like "Python", "replit", "AI", etc.), it adds the title to a list and prints it along with the corresponding link. This is a simple web scraping and data filtering script that searches for specific words in the titles of articles on the given website and displays the titles with their corresponding links.
1
1

0

Fornesus Blog Web ScraperThis project uses BeautifulSoup4 to scrape data from my blog, Fornesus Blog , particularly heading, paragraph, and other specified HTML tags of interest. I also formatted said data to be human-readable.
0
0


0
kayak-scrawlerselenium and bs4 crawler + scraper to obtain flight listing info from kayak.com
install dependencies + setup dev environment
git clone https://github.com/bkataru/kayak-scrawler.git
cd kayak-scrawler
poetry install
usage
python main.py
`
1
0